asynq
Asynq is a Go library for queueing tasks and processing them asynchronously with workers. It’s backed by Redisand is designed to be scalable yet easy to get started.
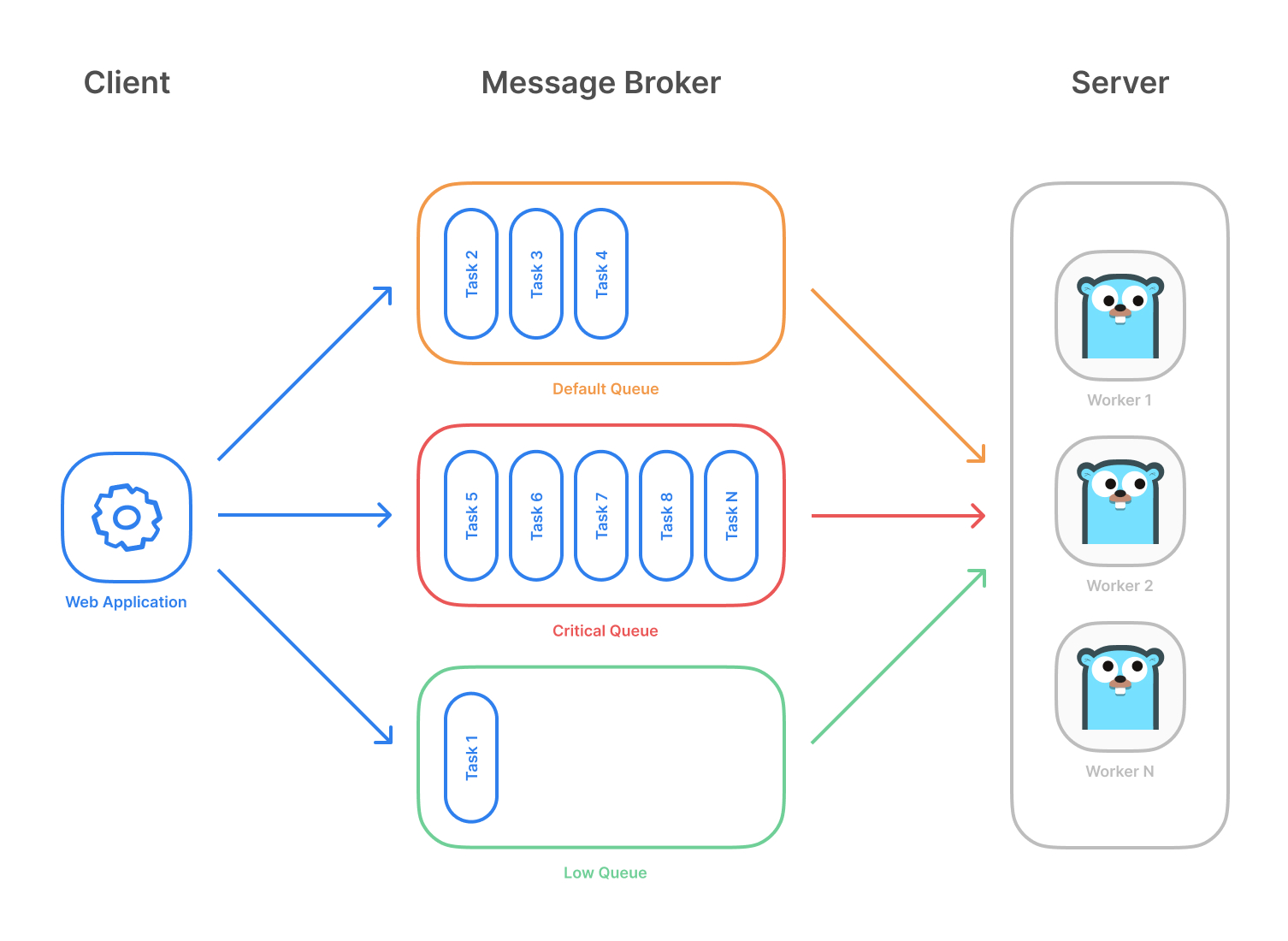
Highlevel overview of how Asynq works:
- Client puts tasks on a queue
- Server pulls tasks off queues and starts a worker goroutine for each task
- Tasks are processed concurrently by multiple workers
Task queues are used as a mechanism to distribute work across multiple machines. A system can consist of multiple worker servers and brokers, giving way to high availability and horizontal scaling.
taskq
taskq is brought to you by ⭐ uptrace/uptrace. Uptrace is an open source and blazingly fast distributed tracing tool powered by OpenTelemetry and ClickHouse. Give it a star as well!
Features
- Redis, SQS, IronMQ, and in-memory backends.
- Automatically scaling number of goroutines used to fetch (fetcher) and process messages (worker).
- Global rate limiting.
- Global limit of workers.
- Call once – deduplicating messages with same name.
- Automatic retries with exponential backoffs.
- Automatic pausing when all messages in queue fail.
- Fallback handler for processing failed messages.
- Message batching. It is used in SQS and IronMQ backends to add/delete messages in batches.
- Automatic message compression using snappy / s2.
goque
Goque provides embedded, disk-based implementations of stack and queue data structures.
Motivation for creating this project was the need for a persistent priority queue that remained performant while growing well beyond the available memory of a given machine. While there are many packages for Go offering queues, they all seem to be memory based and/or standalone solutions that are not embeddable within an application.
Instead of using an in-memory heap structure to store data, everything is stored using the Go port of LevelDB. This results in very little memory being used no matter the size of the database, while read and write performance remains near constant.
Features
- Provides stack (LIFO), queue (FIFO), priority queue, and prefix queue structures.
- Stacks and queues (but not priority queues or prefix queues) are interchangeable.
- Persistent, disk-based.
- Optimized for fast inserts and reads.
- Goroutine safe.
- Designed to work with large datasets outside of RAM/memory.
faktory
At a high level, Faktory is a work server. It is the repository for background jobs within your application. Jobs have a type and a set of arguments and are placed into queues for workers to fetch and execute.
You can use this server to distribute jobs to one or hundreds of machines. Jobs can be executed with any language by clients using the Faktory API to fetch a job from a queue.
Basic Features
- Jobs are represented as JSON hashes.
- Jobs are pushed to and fetched from queues.
- Jobs are reserved with a timeout, 30 min by default.
- Jobs
FAIL‚d or notACK‚d within the reservation timeout are requeued. - FAIL’d jobs trigger a retry workflow with exponential backoff.
- Contains a comprehensive Web UI for management and monitoring.
xsync, MPMCQueue
A MPMCQeueue is a bounded multi-producer multi-consumer concurrent queue.
Based on the algorithm from the MPMCQueue C++ library which in its turn references D.Vyukov’s MPMC queue. According to the following classification, the queue is array-based, fails on overflow, provides causal FIFO, has blocking producers and consumers.
The idea of the algorithm is to allow parallelism for concurrent producers and consumers by introducing the notion of tickets, i.e. values of two counters, one per producers/consumers. An atomic increment of one of those counters is the only noticeable contention point in queue operations. The rest of the operation avoids contention on writes thanks to the turn-based read/write access for each of the queue items.
In essence, MPMCQueue is a specialized queue for scenarios where there are multiple concurrent producers and consumers of a single queue running on a large multicore machine.
To get the optimal performance, you may want to set the queue size to be large enough, say, an order of magnitude greater than the number of producers/consumers, to allow producers and consumers to progress with their queue operations in parallel most of the time.
machinery
Machinery is an asynchronous task queue/job queue based on distributed message passing.
taskqueue
Tasqueue is a simple, lightweight distributed job/worker implementation in Go.
Concepts
tasqueue.Brokeris a generic interface to enqueue and consume messages from a single queue. Currently supported brokers are redis and nats-jetstream. Note: It is important for the broker (or your enqueue, consume implementation) to guarantee atomicity. ie : Tasqueue does not provide locking capabilities to ensure unique job consumption.tasqueue.Resultsis a generic interface to store the status and results of jobs. Currently supported result stores are redis and nats-jetstream.tasqueue.Taskis a pre-registered job handler. It stores a handler functions which is called to process a job. It also stores callbacks (if set through options), executed during different states of a job.tasqueue.Jobrepresents a unit of work pushed to a queue for consumption. It holds:[]bytepayload (encoded in any manner, if required)- task name used to identify the pre-registed task which will processes the job.